

58·
2 months agoYes, welcome
Expert developer, Buddhist
Yes, welcome

Whoa! You can get energy from gravity and spin?? Who would have guessed
No cap that might actually keep without boiling your bottles, you have on your hands a tomato shrub XD
Ah my thermometer only reads fahrenheit, so you know I’m naturally confused about temperatures
That’s true, I love taking a hot water bath, and it’s been completely safe so far
Today I learned that people do canning at home without a proper pressure cooker
VPNs don’t help here, the website asks you for your driver’s license. Tbf giving your credit card to them is typically enough for them (big tech + govt) to construct a full profile of who you are anyway, and that was the original “age gate” – though there are some services that make CCs modestly privacy preserving – not the case for IDs

Everything is customizable if you are brave enough with the code :)
But yeah gnome is known for breaking changes & rewrites. As a result, Cosmic desktop was born to be more stable and reliable with plugins. That’s ~alpha. But if you truly wanna DIY, then the tiling window managers are king. Stuff like dwm and awesomewm where you configure every part of the UI and can easily make your own widgets
What an era. Was kinda the most unbalanced moba, where a single high skill player could dominate both teams. Good time to be a mid ganker carry

The most interesting part of this take is that JD Vance is very much in the big tech friends circle with Thiel and Musk. But I’m sure they can run some antitrust against their enemies at Google or whatever
I remember one internship in college, I realized that after 4 months of work, the result was 15k lines less code than when I started. I figured out new ways to structure the system so it was much easier to write and maintain, while actually adding features. That felt great
And yeah, there are many ways for it to happen. Ex. someone was shipping the tests with the code and decided to stop, debug symbols being removed, inlined dependencies being externalized, maybe a new version of a UI toolkit has extra icons built in
Efficiency can gently creep in. What blows my mind is that this is averaged out across so many packages at once. And sure, sometimes it goes up too, but nothing like Windows/OSX. It’s really cool that you can make a Linux that will fit into ~any space you want, whereas the min requirements for Win11 include 64gb of hd
Out of all the comments here hahaha this is the one that gets me lmao
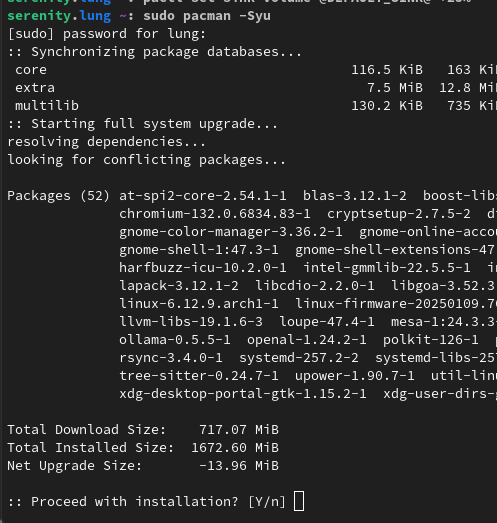
You haven’t had an update with less than 52 packages?? Ever??

Well, I took the time to read the whitepaper, and it’s yeah, pretty dumb sounding. The gist is that it’s p2p post sharing with lots of captchas & a crypto edge that it probably doesn’t need https://img1.wsimg.com/blobby/go/eb02f20b-e787-4a02-b188-d0fcbc250ba1/pleb.tex-6d2e1bf.pdf
The similarities to Lemmy are substantial, it’s just not on activitypub, but rather its own pubsub thing. If you want to host data, you still have to keep a node running at all times, it’s not the case that “there are no instances”. Those instances can moderate the content, so it’s not the case that “there’s no moderation.” The whitepaper mentions that “its possible to delegate running a client to a centralized server…” rather than having to have a fat syncing client running on your own machine … in lemmy, it’s more like “its possible to run your own node if you want”. Plebbit doesn’t care about maintaining history of posts, it expects that servers will go down over time, and the data will be lost. Lemmy is pretty similar in that regard too, if all instances hosting the data go down, then it’s lost. The expected outcome is that there’s a handful of big nodes, as is the typical result of this form of “decentralization” - same as Lemmy, Email
Ultimately, I don’t see Plebbit doing anything particularly smarter/better, and having private/public key cryptography involved doesn’t really matter. They talk about blockchains and using coins as anti-spam mechanisms, but I don’t see why that’s relevant to the implementation
Then I read that chat apps and YouTube would not be banned, and scoffed
Literally chat apps are social media. You can post stories and pump memes and news. You can even have bots that scrape and post content. YouTube is just a matter of checking a box whether it’s “for kids” and they already do that. Basically the whole thing is stupid
Y’know, you’re right & that’s wild. I guess I should have known, but didn’t assume that they have like 600m in unrelated investments. Though the burn rate is quite a lot too, so they probably would scale back browser dev a lot if it lost its profitability & become a pure VC kinda org
Not only does it need to do everything from memory management to job scheduling, it also has all of the UI and graphics driver complexity blended in. Usually that’s a different layer that the kernel historically didn’t worry about, it would be as if GTK is part of Linux, along with the programming language. Then there’s shit like WebAssembly and WebGL, databases, sandboxing, permissions, user management… A Brower is like a cross platform OS built to run on another OS
The thing is it’s never been more expensive and time consuming to write a browser, it’s bigger scope than a kernel in many ways. Stuff like Epiphany isn’t even close, despite relying on Apple’s webkit. Most distros just push people to Firefox now, despite a history of KHTML and all that. We would need something like the Linux Foundation to pick it up (which runs on corporate sponsorship for a shared resource)
Yeah but in the short term the company will literally go out of business
And somehow breaking even more sites than safari; missing many modern features
{kind=link}
That’s so cool, maybe the first time in the history of humanity that we see open source tax software, that’s guaranteed to be accurate to the law. For one year at least
It runs Scala / Java, and has docker configs, decent documentation. And an ominous message explaining that some parts were too secret to open source so they had to rewrite chunks of it. Overall, it seems like it was a big project just to get this published, and I am impressed they managed it, given the software team was comprised of 3 different agencies and several contractor firms