

511·
2 months ago
cultural reviewer and dabbler in stylistic premonitions

this is a good meme

it’s among the many OSes you can run in an emulator in your web browser at https://copy.sh/v86/
sometimes a footprint represents humanity
sometimes, but in GNOME’s case i think it is not intended to be a human foot but rather the foot of a mythological creature (a gnome). note that it has a squashed aspect ratio compared to a human foot, and also has only four toes.
apparently it’s also problematic in some cultures: https://wiki.gnome.org/Engagement/FootAndCulturalIssue

Is this a spam campaign?
Five of the eleven comments so far (including one from OP) are all recommending the same service; all five are from accounts less than 2 months old with a one or two digit number of comments 🤔
Why memorize a different command? I assume sudoedit just looks up the system’s EDITOR environment variable and uses that. Is there any other benefit?
I don’t use it, but, sudoedit is a little more complicated than that.
from man sudo:
When invoked as sudoedit, the -e option (described below), is implied.
-e, --edit
Edit one or more files instead of running a command. In lieu
of a path name, the string "sudoedit" is used when consulting
the security policy. If the user is authorized by the policy,
the following steps are taken:
1. Temporary copies are made of the files to be edited with
the owner set to the invoking user.
2. The editor specified by the policy is run to edit the tem‐
porary files. The sudoers policy uses the SUDO_EDITOR,
VISUAL and EDITOR environment variables (in that order).
If none of SUDO_EDITOR, VISUAL or EDITOR are set, the
first program listed in the editor sudoers(5) option is
used.
3. If they have been modified, the temporary files are copied
back to their original location and the temporary versions
are removed.
To help prevent the editing of unauthorized files, the follow‐
ing restrictions are enforced unless explicitly allowed by the
security policy:
• Symbolic links may not be edited (version 1.8.15 and
higher).
• Symbolic links along the path to be edited are not followed
when the parent directory is writable by the invoking user
unless that user is root (version 1.8.16 and higher).
• Files located in a directory that is writable by the invok‐
ing user may not be edited unless that user is root (ver‐
sion 1.8.16 and higher).
Users are never allowed to edit device special files.
If the specified file does not exist, it will be created. Un‐
like most commands run by sudo, the editor is run with the in‐
voking user's environment unmodified. If the temporary file
becomes empty after editing, the user will be prompted before
it is installed. If, for some reason, sudo is unable to update
a file with its edited version, the user will receive a warning
and the edited copy will remain in a temporary file.
tldr: it makes a copy of the file-to-be-edited in a temp directory, owned by you, and then runs your $EDITOR as your normal user (so, with your normal editor config)
note that sudo also includes a similar command which is specifically for editing /etc/sudoers, called visudo 🤪
These articles were stolen, by the paywall operators. Elbakyan rescued them from the thieves. 🎉
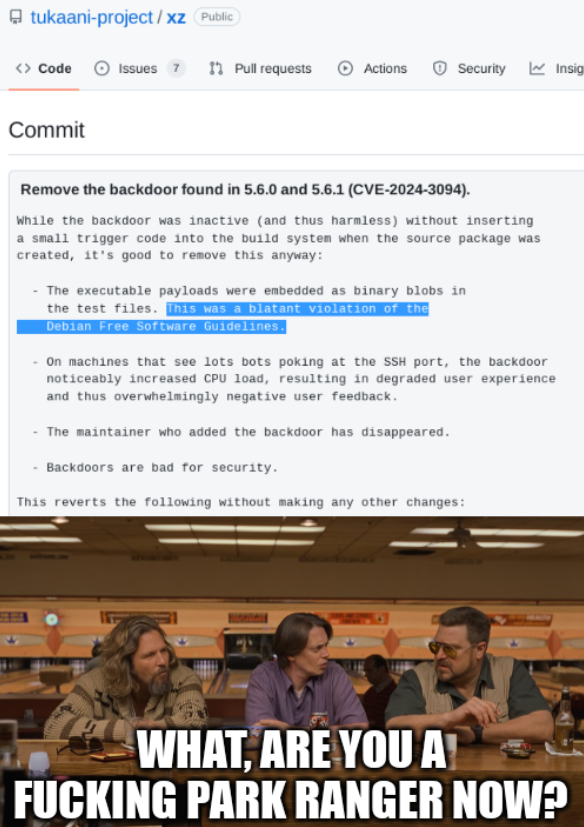
the non-recursive part of this image is mildlyinfuriating

if you’ve never used ed(1) technically it’s illegal for you to say “it’s a UNIX system, i know this”
yep. (see my other comment in this thread)
The three currently-maintained engines which (at their feature intersection) effectively define what “the web” is today are Mozilla’s Gecko, Apple’s WebKit, and Google’s Blink.
The latter two are both descended from KHTML, which came from the Konquerer browser which was first released as part of KDE 2.0 in 2000, and thus both are LGPL licensed.
After having their own proprietary engine for over two decades, Microsoft stopped developing it and switched to Google’s fork of Apple’s fork of KDE’s free software web engine.
Probably Windows will replace its kernel with Linux eventually too, for better or worse :)
How else are Chrome, Edge, Brave, Arc, Vivaldi and co getting away with building proprietary layers on top of a copyleft dependency?
They’re allowed to because the LGPL (unlike the normal GPL) is a weak copyleft license.
BSD tells me the team probably wants Ladybird to become not just a standalone browser but also a new competing base for others to build a browser on top of
")
it’s about the ladybird browser. i edited my comment to add details.
with mandatory male pronouns for users in the documentation.
(and no politics allowed!)
this issue was resolved eventually by another dev; afaik the lead dev stopped commenting on it after he closed a PR and said people who wanted to remove the docs’ implied assumption of users’ maleness were “advertising personal politics”.
edit: ok, i went and checked, here are the details:
https://github.com/SerenityOS/serenity/pull/6814 is the first PR he closed in 2021 saying “This project is not an appropriate arena to advertise your personal politics.”
https://github.com/SerenityOS/serenity/pull/24648 is the PR where it was eventually fixed, after it was publicized in july 2024
here https://xcancel.com/awesomekling/status/1808294414101467564 the day after the fix was merged, he sort-of almost apologized, while also doubling-down on his defense of his decision to reject the first PR 🤡
https://en.wikipedia.org/wiki/Ladybird_(web_browser) was later spun out of SerenityOS in to its own project
https://kernel.org/pub/linux/kernel/SillySounds/english.ogg (from back when many english speakers were still insistent that the i in Linux should be pronounced “eye”)
I’m confused as to why this 404media story neglected to link to the post in question.
to get from this article to the post that it is about, i had to type in the bsky username from the screenshot and scroll through the timeline. to save others the effort:
https://bsky.app/profile/marisakabas.bsky.social/post/3liwlwvvq6k2s is the post which was removed.
https://bsky.app/profile/marisakabas.bsky.social/post/3lj3yrzc6is2p is the thread about it being removed and later restored.
would you recommend that book for learning regular expressions as a non CS guy?
Absolutely, it’s an excellent book which I highly recommend.
The latest edition (3rd) is almost 20 years old, but I don’t think regex has actually changed substantially since then so it should still be very useful. (I read the 2nd edition cover-to-cover and enjoyed it enough that I bought the 3rd when it was released 😀)
If you’re going to buy a physical copy from amazon you should use the author’s link here to give him slightly more money for it. But if you just want a PDF I see one is available here.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The industry will take whatever steps it needs to protect itself and protect its revenue streams ... It will not lose that revenue stream, no matter what ... Sony is going to take aggressive steps to stop this. We will develop technology that transcends the individual user. We will firewall Napster at source – we will block it at your cable company. We will block it at your phone company. We will block it at your ISP. We will firewall it at your PC ... These strategies are being aggressively pursued because there is simply too much at stake. - Steve Heckler, senior vice president of Sony Pictures Entertainment Inc, August 2000
quote from https://web.archive.org/web/20010201204600/http://www.nyfairuse.org/sony.xhtml
via https://en.wikipedia.org/wiki/Sony_BMG_copy_protection_rootkit_scandal